【仕組みから理解】理想の英語リーディング力とは?

効率的に勉強していくために、前もって仕組みを理解しておきたい。
今日はこんな疑問に答えます。
本記事の内容
- リーディングのメカニズムとは?【脳内で行われている6つの情報処理】
- 目指すべき理想の英語リーディング力とは?
リーディング中、頭の中で何が起きているかしっかりと把握し、適切にその後の学習を進められるようにしていきましょう。
なお、今回も主観に偏った内容にならないよう、応用言語学、言語習得論からの文献を参考にしつつ、解説して行きたいと思います。
それでは行きましょう。
リーディングのメカニズムとは?【脳内で行われている6つの情報処理】

リーディングは、書き手が書いた文字情報を読んで、その内容を理解する行為です。
それを「脳内での情報処理」が可能にしています。
(なお「処理」とは、頭の中で行う「計算」、もしくは「頭を働かせること」くらいにお考えください。)

さらにこの脳内での処理は、大まかに以下の段階に分けることができます。
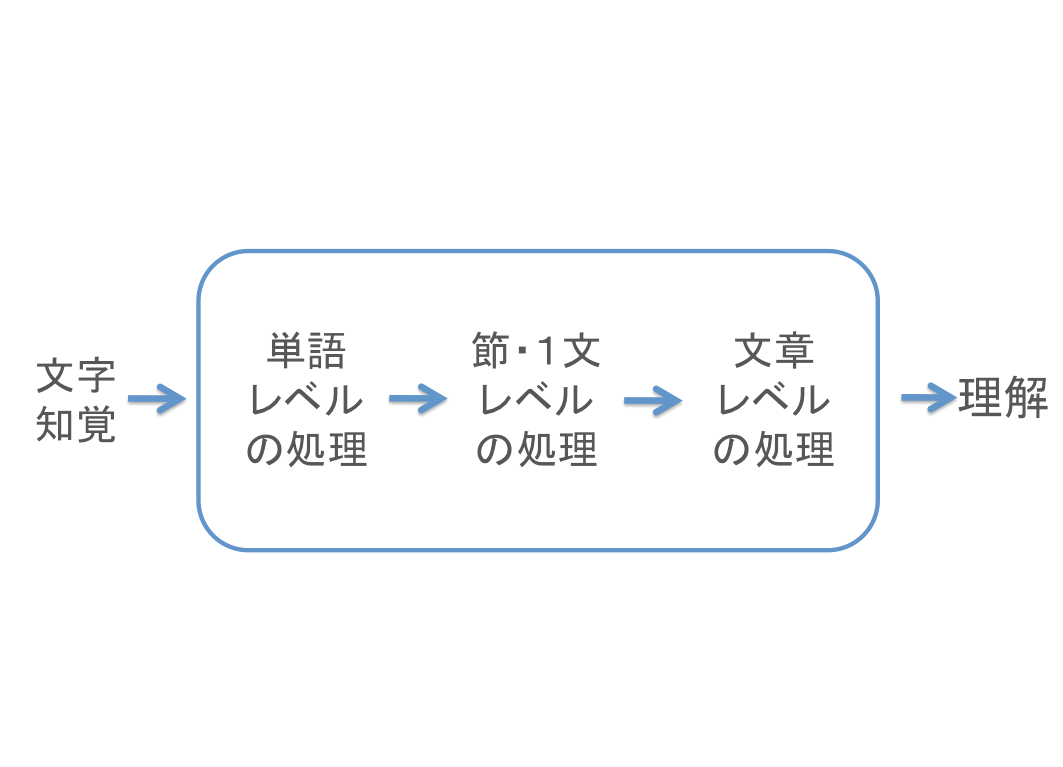
上記のようになります。
ではより具体的に、リーディング中、我々の頭の中ではどんな処理がなされているのでしょうか?
現在、研究によって、次のような処理プロセスを踏んでいることが明らかになっています。
以下、門田(2015)、Grabe (2009)、Grabe and Stoller (2011) のまとめです。
リーディングを可能にする6つの処理ステップ

このように、大きく6つの処理ステップが噛み合いながら、全体として効率的なリーディングを可能にしています。
では①〜⑥を、詳しく順番に見ていきましょう。
①単語の認知(Word recognition)
リーディングは、まず単語の認識から始まります。
文の中で「どんな単語が使われているのか」、「一体その単語はどんな単語なのか」を認識するのが、単語認知(Word recognition)です。
当然これをするには、あらかじめ頭の中に、その単語の知識がストックされていないといけません。
人間は、脳の中にあらゆる語彙情報を蓄えている心の辞書(=メンタルレキシコンと呼ばれます)を備えています。ここに、その単語に関するあらゆる情報(スペリング・発音・意味など)もストックされています。
目にした単語をきっかけに、
という作業をするのが、単語認知です。
特に、我々が日本語を使う場合、英語ネイティブが英語を使うような場合は、ほぼ自動的に、かつ無意識的にこの照合 & 単語の認識が行われています。
②音韻符号化
単語認知では単語の意味も引き出されますが、そこで重要になるのが「音韻符号化」というプロセスです。
音韻符号化とは、①で視覚的に認識した単語を、一旦頭の中で「音声化」する処理です。
例えば、英文を読んでいるとき、気がついたら頭の中で自然と発音していた、という経験はないでしょうか?
人間は文字を読むときでも、このような音声化を自然に行っています。
「単語の意味」は、「文字」よりも「音」と強く結びついている!
実は、人間が単語の意味を認識する際、
という流れを踏むことが、意味への自然なアクセスルートとして知られています。
例えば、”coffee” という単語の例だと以下のようになります。

なお、ルートBのような、直接「文字 → 意味」と認識するルートも、存在は認められています。
ですが、ルートAのような「文字 → 音声化 → 意味」が、人間のより自然な意味へのアクセスの仕方として考えられています。
この意味で、文字を音声化(音韻符号化)する練習も、リーディング力の向上には欠かせません。
リーディングは「音はあまり関係ない」と思いがちですが、ここが意外な盲点でもあります。
以上ここまでで、目で見た文字から単語の意味を見出す過程でした。
なお①②の処理は “Decoding” と呼ばれます。
③文法の処理(統語処理)
次は1単語の範囲を超えます。
複数の単語の並びに対して、文法的な処理を施していくのがこのプロセスです(統語処理とも言われます)。
具体的には、目の前に並んだ単語が、どのような語順や文構造で成り立っているのかを解析します。それに加え、限定詞や代名詞・時制・法などあらゆる文法項目についても処理を行います。
正しく意味を理解するために、文法が果たす役割は非常に大きいです。
例えば以下です。
語順が重要と分かる例
(2) The woman hit the man.
(↑門田, 2015, p.78より)
英語は「語順」が意味の違いに直結する言語です。
ご覧の通り、(1)と(2)では同じ単語が使われていますが、語順が異なります。結果、全然違う意味になっています。
次はどうでしょうか?
時制、冠詞、前置詞 etc.が重要と分かる例
(4) The man fired from the rifle factory screamed at his boss.
(↑Grabe, 2009, p.29より)
この場合も(3)と(4)で同じ内容語が使われています。
ですが、(3)はほぼ意味が不明だと思います。一方(4)には、時制、冠詞、前置詞といった文法情報が加わっています。これにより、かなりくっきりと文の意味がとれるはずです。
これが文法の力です。
このように文法処理は、
… clarify how words are supposed to be understood
(Grabe and Stoller, 2011, p.16)
= 単語どうしがどのように理解されるべきかを明確にする
(訳:松田)
という役割を果たしており、リーディングで重要なプロセスとされています。
④意味処理
ここまでで、単語の意味と、単語の並びについての規則性(文法)がわかりました。
それらの情報をもとに、「節・1文単位での意味を掴む」のが意味処理です。
各文ごとに、「誰(何)が、誰(何)に、何をしたのか」といったような出来事や内容を掴んでいきます。
ここでつかむ1文ごとの意味内容は、建物を建てる際のブロックのようなものです。これらをもとにして、次の文章レベルでの意味把握が可能になります。
⑤文章の要旨を掴む
ここからは1文を超え、文章全体を通しての意味把握のプロセスです。
多くの場合、文字情報は1文だけで終わることはありません。複数の文を重ねることによって、書き手はあるメッセージを伝えようとします。
読み手としては、④で得られる各文の内容を関連づけながら、文章全体でどんな内容なのか、メインポイントを見出していきます。
人は1文ずつ丸覚えしているわけではない
人は1文ずつ読んでいったとしても、各文のすべての情報を記憶に残しているわけではありません。
特に、全体を通して繰り返し出てくるような重要度の高い内容は、脳内で繰り返し活性化が起こり、メインポイントとして記憶に残ります。
一方で、関連が薄く重要度の低い情報は、活性化が途絶え、記憶から消えて行きます。
このような情報の取捨選択が行われつつ、文章の内容を把握して行きます。
余談ですが、リーディングの試験で文章を読んで要約するような問題や、仕事で何かを読んで要約しないといけない場面では、①〜⑤までの処理スキルが問われていると言えるでしょう。
⑥文章を解釈する(スキーマ処理)
理解の最終段階です。
⑤はあくまで書かれているテキストからの、情報の抽出でした。
それに対し、テキストには直接書かれていないような意味を、読み手の方で引き出すプロセスが「解釈」です。
解釈の例
例えば、ある機関が以下のような統計レポートを出したとします。
これを読んで、以下のような理解を得るかもしれません。
この下線の部分は、上の文には書いていません。読み手側によって導き出された「解釈」と言えます。
「解釈」 = 「書かれてる内容」×「読み手の知識」の掛け合わせ
大変なことだと理解できたのは、読み手の中に、ある種「人口」に関連した事前知識があったからと言えます。
例えば、
ということを知っていて「大変だ」と理解したのかもしれません。
逆に、まだ経済のことをよく知らない幼い子どもは、このような知識がないと考えられます。なので「人口が●●人から○○人になった」ということだけをそのまま理解して終わるでしょう。
このように理解とは、それまで自分が生きてきた中で得た経験や背景知識をもとに、書かれている内容に対して何かの「推論」をしたり「予測」したりするような行為も含んでいます。
また、テキストを解釈するために使われる、読み手の頭の中にある背景知識は「スキーマ」と呼ばれています(An, 2013)。
このことから、⑥の処理プロセスは「スキーマ処理」とも呼ばれます。
⑤に加え、これも文章理解の1つの形態です。
リーディングのメカニズム:補足 & まとめ

リーディングのメカニズム(再掲)

このように、リーディング中、頭の中ではこのような6つの情報処理がなされ、「理解する」という行為を達成しています。
各処理はお互いに助け合っている
ちなみに、単語や1文の意味がわかるから全体の意味がわかるのか?文章全体の意味がわかるから1文、1単語の意味がわかるのか?どちらでしょうか。
前者のパターン、
というのは想像しやすいと思います。
ただ、理解の仕方はそれ1方向だけではないことが研究で明らかになっています。
例えば、リーディングをしていて、馴染みのない単語や1文に出会った場合。
それでも文章全体の話の流れや、そのトピックについてのスキーマ(⑤⑥)などから、その1文の意味の予測がつくことがあります。それが巡り巡って、文章全体での理解度を深める助けになることがあります。
このようにリーディングは、単語の処理から順に積み上げ理解に到達するという一方で(Bottom-up処理)、⑤⑥のような上位の理解が下位の処理を助けるかたち(Top-down処理)で、全体としてうまく回っています。

このような処理のサイクルをうまく回すことで、リーディングという複雑な行為が可能になっています。
ではこのようなリーディングのメカニズムからわかる、目指すべきリーディング力とはどんなものでしょうか?
目指すべき理想の英語リーディング力とは?

結論から書くと、
- 単語〜1文レベルの処理(①〜④)を「無意識的に」こなせる
- それによりリーディング中は、文章レベルの処理(⑤⑥)の方に集中して取り組める
が理想のリーディングと言えます。
なぜこのバランスが必要かは、実際のリーディングを思い浮かべてみるとよくわかります。
よく慣れた言語のリーディング
例えば、我々が日本語を、英語ネイティブが英語を読む場合。リーディングに必要な①〜⑥の処理のどこに注力しているでしょうか。
おそらく多くの人が、⑤や⑥の、文章全体の内容をつかむことに、意識的に取り組んでいると思います。
一方で、「この単語は..」「この文法は..」などといちいち考えてはいないと思います。
歩くとき、右手足、左手足の動きをいちいち意識していたらうまく歩けないのと一緒です。細かく全てのことに気を止めていると、スムーズに読み進めることはできません。
では、単語や文法の処理を「無視している」のか?というとそうではありません。
母語のリーディングの場合は、細かいレベルの処理は、身体や頭が勝手に動くほどに「自動化」されています。
そのおかげで、文全体の内容の方に集中できるのです。
外国語におけるリーディング
反対に、英語でリーディングするとき。
特に初学者の場合は、単語や文法に関する処理は、ほとんど自動化されていません。
英文を読むときに、単語や文構造を理解することに苦労してしまい、結局どんな内容だったのかは頭に残ってない、ということがあるのはこのためです。
これは人間の脳内のキャパシティ(認知資源)が限られていることから起きる現象です。
英語という言語に慣れていないので、単語・文法といった言語的な処理(主に①〜④)に多くのリソースが割かれてしまい、それより文章全体の理解(⑤⑥)が邪魔されて取り組めていないことが原因となっています。
「スキルの自動化」が鍵
なので、①〜④のような「言語的な処理」に対しては、練習を通して頭が勝手に(無意識に)動いてくれるようにすることが重要です。
これを第二言語習得研究では「自動化」といいます。
つまり、「覚えた単語や文法知識を、スキルとして『使える』ように練習していく」ということです。
諸々の細かいスキルを無意識でサクサクできるほどに自動化することで、本来のリーディングの目的である、「文章全体での内容把握や理解」にしっかり集中できるようになります。
これについて学者のJohnson(2008)は、以下のように表現しています。
The role of automatization [中略] is therefore to free valuable channel capacity for those more important tasks which require it.
(p.103)
= ゆえに自動化の役割は、貴重な脳内のキャパシティを、それを必要とするより重要なタスクのために解放することである。
(訳:松田)
「より重要なタスク」とは、リーディングの場合、⑤⑥のようなものを指します。
この自動化を通して、Bottom-upとTop-downの処理サイクルがうまく回りやすくなり、全体としてスムーズに安定して読み進められるようになっていきます。
目標:長文を目にした瞬間「ウッ!」とならないこと
英語の長文を目にした瞬間、日本語を見るときに感じない威圧感を感じてしまうなら、それは頭に負荷がかかっているということであり、以下のように①〜④を自動化する必要があります。
- ①単語認知 → 瞬時に「この単語!」と認識できるように。
- ②音韻符号化 → その単語を瞬時に音声化し、意味を認識できるように。
- ③文法処理 → 瞬時に文法構造を見抜けるように。
- ④意味処理 → ①〜③をもとに、1文単位での意味がすぐ思い浮かぶように。
このような瞬時力をつけるための練習を意識的に行い、リーディング中にかかる負担を取り除いていくことが重要です。
それによって、母語のときと同じように、
- リーディング中は、文章全体の理解に集中することを基本モードに
- 単語や文法は無意識に頭が動いてくれ、何か問題があったときだけ注力すればいい
という状態を作りましょう。
結論:理想の目指すべきリーディング力

このようなバランスを目指すことが、リーディングは重要です。
まとめ

- リーディングには6つの処理ステップが関わっている
- 単語レベル〜1文レベルの処理を普段の学習でしっかりと自動化
- リーディング中は、文章の内容理解に集中できるよう目指すべき
という内容でした。
このようなメカニズムを把握した上で、どのような対策が必要か考をえ、練習法を選んでいくことが大切です。
なお、1つ具体的な練習法としては音読があります。
音読について重要なことは、以下で丸っとまとめています。
英語音読の総まとめ【基礎知識〜実践テクニックまで網羅】
英語の音読について、網羅的に理解するためのまとめ記事です。音読についての基礎知識〜実際に練習するにあたっての技術的なテクニック論まで、計15を超える記事で解説。音読について幅広く理解し、練習の密度を最大限上げて行きたい方はぜひチェックください。
よければぜひ参考ください。
おわり
ーーー
【参考文献】
An, S. 2013. Schema theory in reading. Theory and Practice in Language Studies, 3 (1), pp.130-134.
Grabe, W. 2009. Reading in a second language: moving from theory to practice. Cambridge: Cambridge University Press.
Grabe, W. and Stoller, F. L. 2011. Teaching and researching reading. 2nd ed. New York: Routledge.
Johnson, K. 2008. An introduction to foreign language learning and teaching. 2nd ed. Edinburgh: Person Education Limited.
門田修平. 2015. 『シャドーイング・音読と英語コミュニケーションの科学』 東京:コスモピア.